|
|
Расширения языка Transact-SQL
В новой версии Microsoft SQL Server 2005 язык Transact-SQL переработан для обеспечения соответствия стандарту ANSI и расширения его функциональных возможностей. Он стал более логичным и завершенным. Одним из усовершенствований Transact-SQL является включение полной поддержки технологии IntelliSense, что обеспечивает интерактивную подсказку параметров и интеллектуальное завершение для всех команд, редактируемых в среде SQL Server. Другое новшество относится к оператору TOP. В SQL Server 2000 для этого оператора использовались фиксированные константы - TOP 5 (верхние 5 строк). А в SQL 2005 к оператору TOP можно привязывать любое выражение в пределах правил Transact-SQL, включая использование переменного или скалярного подзапроса. Оператор TOP поддерживают предложения INSERT, UPDATE и DELETE. В SQL 2005 усовершенствована обработка аварийного прерывания: язык Transact-SQL дополнен новыми предложениями Try...Catch...Finally. Их использование позволяет отслеживать ошибки, вызвавшие прерывание, без потери контекста транзакции, что обеспечивает полное ее восстановление. Обработка прерывания возможна и в SQL Server 2000, но без сохранения детального контекста прерванной транзакции, что делает невозможным ее полное восстановление. Кроме того, значительной переработке подверглись инструкции DDL (Data Definition Language, язык определения данных). Например, для того чтобы создать любой объект, необходимо воспользоваться только операторами языка DDL, а не использовать хранимые процедуры, как было до MS SQL 2005. Новые операторы языка определения данных (DDL)В новой версии сервера решена проблема единства методов создания, модификации и удаления объектов. Все объекты сервера создаются оператором CREATE, модифицируются оператором ALTER, а удаляются оператором DROP. Данный подход стандартизует методы управления объектами, что упрощает разработку приложений и администрирование системы. Новые операторы языка определения данных приведены в табл. 1.1, а их использование будет описано в следующих главах книги.
Новые операторы языка манипулирования данными (DML)Язык манипулирования данными (Data Manipulation Language, DML) - самый используемый модуль команд языка Transact-SQL. В девяноста случаях из ста применяется именно он. В языке появилось много новых конструкций: CTE-выражения, PIVOT, UNPIVOT, TOP и многие другие. Основные новшества, появившиеся в языке, будут рассмотрены в этом разделе. CTE-выраженияЧасто возникает потребность создания выражений для временных вычислений. Однако в предыдущих версиях сервера такое выражение, не оформленное как хранимая процедура, функция или просмотр (View), рассматривалось как динамическая строка и компилировалось при каждом вызове. Потребность в рекурсивных вычислениях решалась либо через курсоры, либо через операции с временными таблицами. Для решения этих задач в новой версии сервера могут быть использованы CTE-выражения (common table expression). Эта новинка позволяет определить виртуальное представление, которое можно использовать в другом операторе (например, SELECT) языка манипулирования данными. Описание СТЕ - временный именованный результирующий набор, который конкретизируется запросом запуска с ключевым словом WITH, может служить заменой субзапросу или использоваться в View, его можно использовать с SELECT / INSERT / UPDATE / DELETE и для рекурсивных вычислений. CTE начинается с оператора WITH. Множественные CTE разделяются запятыми. Синтаксис
Пример использования CTE-выражения для упрощения читаемости запросов показан в листинге 1.1.
Важной особенностью CTE является то, что при многократном использовании CTE в запросе сервер может оптимизировать вызовы и вызывать ее только один раз (листинг 1.2).
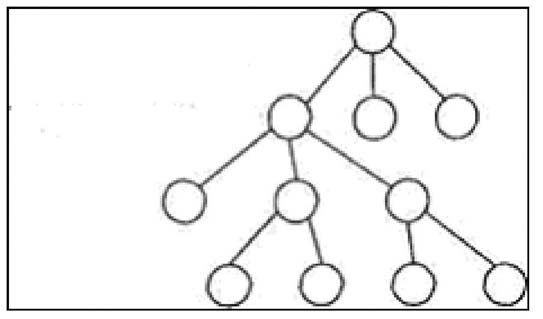
Но, наверное, одно из самых полезных применений CTE, - выполнение рекурсивных вычислений, в том числе по древовидным структурам (рис. 1.1).
Описание Рекурсивное CTE содержит три части:
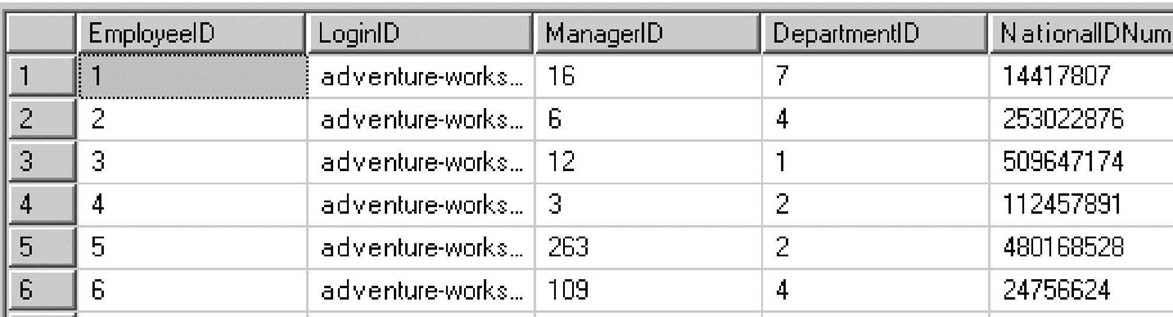
Использование CTE для рекурсивного прохода по дереву, представленному в виде таблицы (рис. 1.2), показано в листинге 1.3.
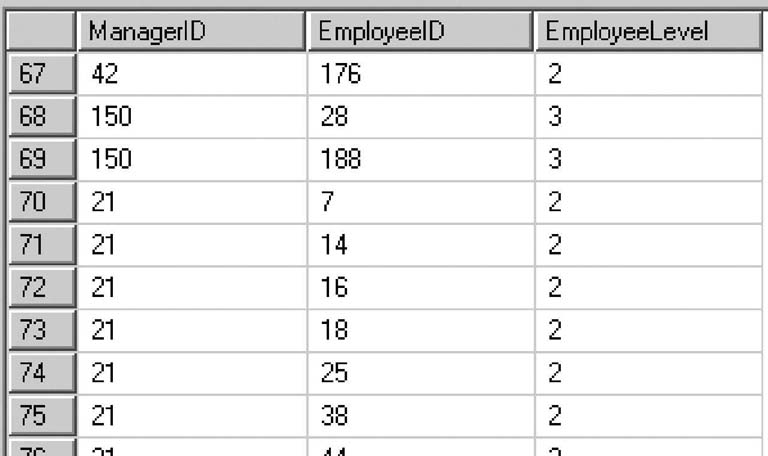
Запрос выводит идентификаторы начальника и подчиненного и уровень подчиненности (рис. 1.3).
Операторы PIVOT и UNPIVOTSQL Server 2005 представляет два новых реляционных оператора - PIVOT и UNPIVOT, которые могут использоваться в выражении FROM. Эти операторы выполняют определенные преобразования над входным набором данных и выдают результирующий набор. Оператор PIVOT превращает строки в столбцы, выполняя при необходимости агрегацию. Он расширяет входной набор, основываясь на заданном для преобразования столбце и создавая набор вывода со столбцом для каждого уникального значения в столбце для преобразования. В сценарии с открытой схемой вы поддерживаете объекты с наборами свойств, либо неизвестными заранее, либо различными для каждого типа объектов. Пользователи приложения определяют свойства динамически. Вместо предопределения многих столбцов и хранения NULL в таблицах, свойства разносятся по строкам и хранятся только свойства, относящиеся к определенному экземпляру объекта. PIVOT позволяет создавать матричные отчеты для открытой схемы и других сценариев, в которых вы превращаете строки в столбцы, выполняя при этом агрегацию и представляя данные в нужной форме. Оператор UNPIVOT выполняет операцию, противоположную выполняемой PIVOT, - превращает столбцы в строки. Он сужает входное табличное выражение, основываясь на заданном для преобразования столбце. Оператор UNPIVOT позволяет нормализовать данные, ранее денормализованные применением PIVOT. Описание PIVOT Для работы с оператором PIVOT необходимо определить:
Описание UNPIVOT Для работы с оператором UNPIVOT необходимо определить:
Синтаксис PIVOT
Синтаксис UNPIVOT
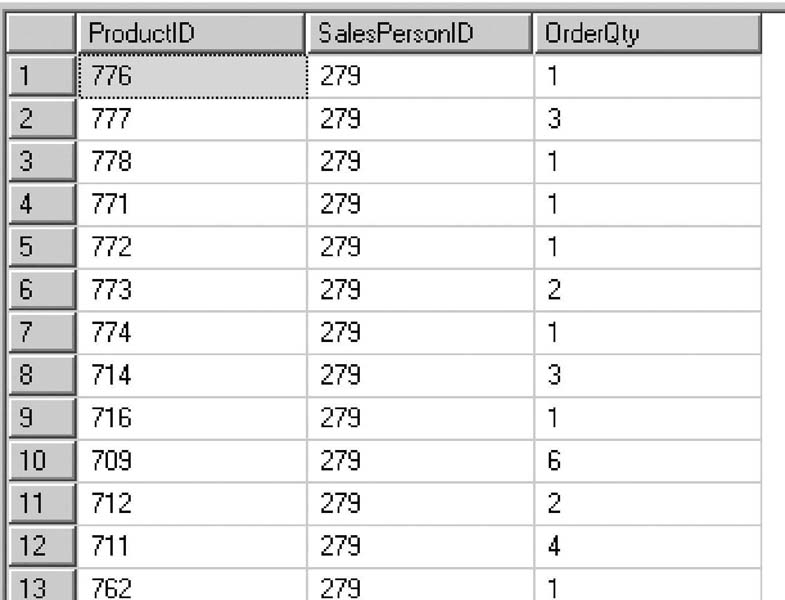
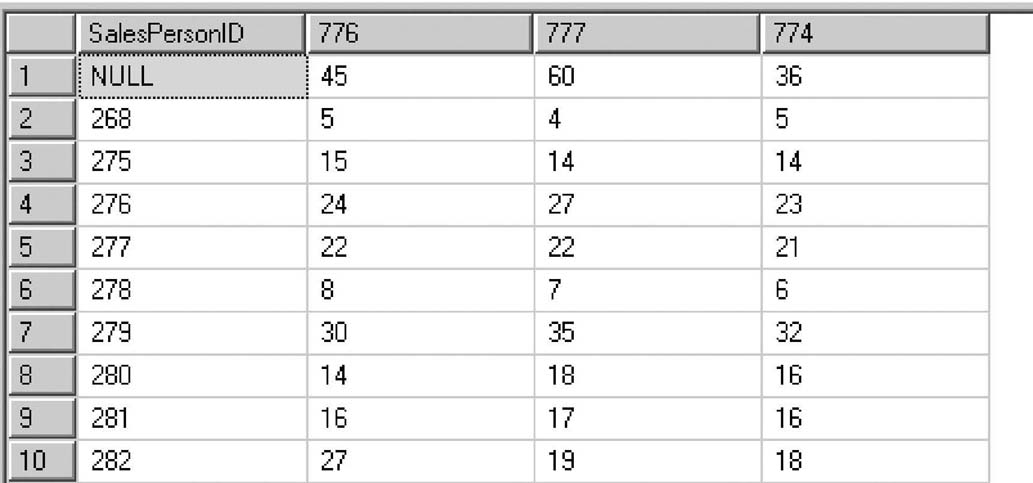
Предположим, надо посчитать, продажу какого количества продуктов с номерами 776, 777, 774 оформили сотрудники отдела продаж. Рассмотрим пример применения операции PIVOT (листинг 1.4) к набору данных, показанному на рис. 1.4.
Результат выполнения оператора PIVOT показан на рис. 1.5.
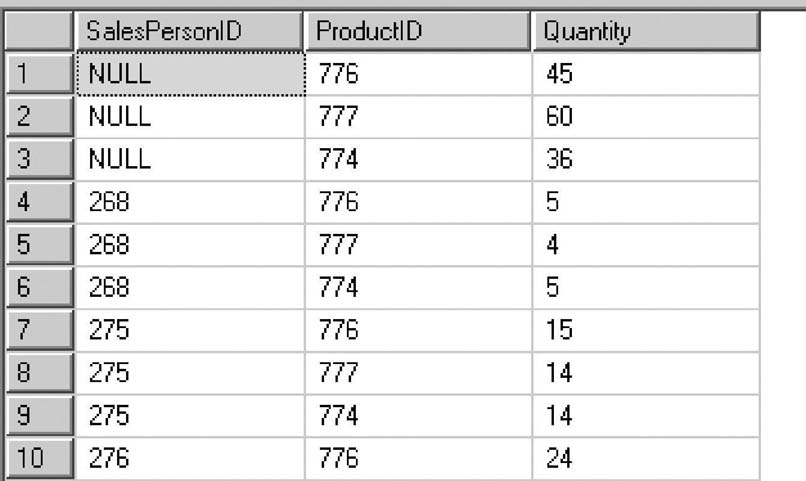
Рассмотрим пример применения оператора UNPIVOT (листинг 1.5) к набору данных, показанному на рис. 1.5.
Оператор UNPIVOT создал обратный транспонированный набор данных (рис. 1.6).
Ключевое слово OUTPUTВ предыдущих версиях MS SQL Server в триггерах использовались специальные таблицы inserted и deleted. Подобная возможность добавлена в MS SQL Server 2005 для операторов языка DML, выполняющих модификацию данных. Чтобы этим воспользоваться, необходимо в DML-выражение добавить ключевое слово OUTPUT. Описание OUTPUT может использоваться в операторах INSERT, UPDATE, DELETE:
Доступ к данным в этих таблицах возможен через table_name.column_name. Синтаксис
Рассмотрим пример использования ключевого слова OUTPUT (листинги 1.6-1.8).
В результате создается временная служебная таблица inserted (рис. 1.7).
Оператор APPLYВ MS SQL Server 2000 впервые появились пользовательские функции: скалярные, подставляемые табличные и многооператорные табличные. Оператор APPLY позволяет ссылаться на табличную функцию в коррелированном подзапросе и вызывать определенную табличную функцию один раз для каждой строки внешнего табличного выражения. APPLY определяется в выражении FROM запроса аналогично реляционному оператору JOIN. APPLY используется в двух вариантах: CROSS APPLY и OUTER APPLY. CROSS APPLY вызывает табличную функцию для каждой строки внешнего выражения. На столбцы внешней таблицы можно ссылаться, как на аргументы табличной функции. CROSS APPLY возвращает унифицированный набор результатов, собранный из всех результатов, возвращенных отдельными вызовами табличной функции. Если табличная функция возвращает пустой набор для данной внешней строки, то эта строка в результате не возвращается. OUTER APPLY похож на CROSS APPLY, но возвращает строки из внешнего набора, даже если табличная функция возвратила пустой набор. Возвращаются значения NULL как значения столбцов, соответствующих столбцам табличной функции. Описание CROSS APPLY - возвращает строки, присутствующие одновременно и в таблице, и в функции. OUTER APPLY - возвращает все строки таблицы независимо от того, возвращаются или нет соответствующие им строки из функции. Синтаксис
Применение операторов CROSS APPLY и OUTER APPLY показано в листингах 1.9-1.11.
Результат запроса на CROSS-объединение показан на рис. 1.8.
Результат запроса на OUTER-объединение показан на рис. 1.9.
В результирующем наборе появились значения NULL, значит, функция не возвратила значения, соответствующие значениям в таблице (подобно функции LEFT OUTER JOIN между таблицами). Функции ранжированияИногда необходимо упорядочить наборы данных частично, но стандартный оператор ORDER BY лишен такой возможности. В новой версии сервера появились четыре функции ранжирования выводимых данных в запросах: RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE(). Ранжирование выполняется внутри "окна", определяемого предложением PARTITION BY. Функции RANK()Описание Функция RANK() возвращает ранг каждой строки внутри "окна", определяемого предложением PARTITION BY. Ранг каждой строки равен рангу предыдущей, увеличенному на единицу. Синтаксис
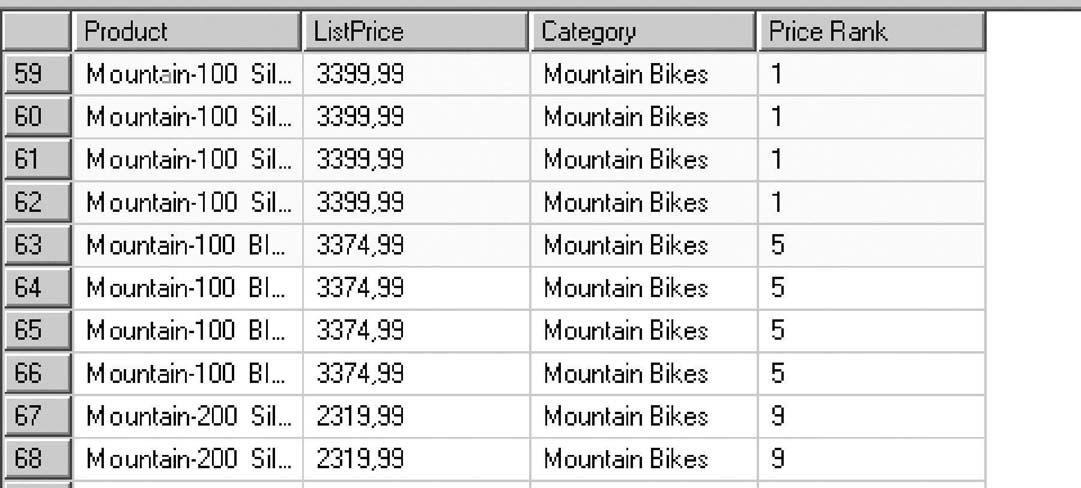
Рассмотрим на примере, как функция RANK() ранжирует множество продуктов по цене продукта внутри "окна", определяемого названием категории (листинг 1.12).
Результат выполнения функции RANK() показан на рис. 1.10.
Однако RANK() может давать некорректный результат; если несколько строк имеют один и тот же rank, то rank следующей строки назначается исходя из количества строк, попавших в "окно" (рис. 1.10). Для решения этой проблемы можно пользоваться функцией DENSE_RANK(). Функции DENSE_RANK()Описание Функция DENSE_RANK() возвращает ранг каждой строки внутри "окна", определяемого предложением PARTITION BY, без пропусков в ранжировании (дыр). Ранг каждой последующей строки равен индивидуальному рангу предыдущей, увеличенному на единицу. Синтаксис
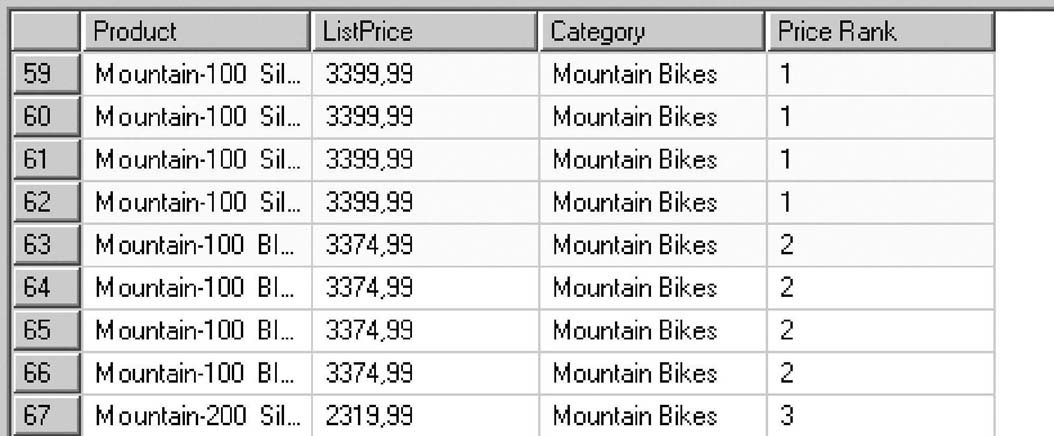
Эта проблема может быть решена с помощью функции DENSE_RANK() (листинг 1.13).
Результат выполнения функции DENSE_RANK() показан на рис. 1.11.
Функции ROW_NUMBER()Функции ROW_NUMBER() определяют место объекта внутри группы однородных объектов, упорядоченных по какому-либо признаку. Описание Функция ROW_NUMBER() возвращает последовательный номер строки внутри "окна", определяемого предложением PARTITION BY, начиная с единицы для каждой первой строки внутри каждого нового "окна". Синтаксис
В листинге 1.14 решается задача определения места товара внутри категории по его цене.
Результат выполнения функции ROW_NUMBER() показан на рис. 1.12.
Функции NTILE()Функция NTILE() выполняет автоматическое разделение множества объектов по группам (категориям) на основании какого-либо признака, например определяет количество ценовых групп товаров по категориям и принадлежность каждого товара к группе. Описание Функция NTILE() делит "окно" (группу), определяемое предложением PARTITION BY, на указанное количество рангов, причем функция "старается", чтобы количество строк в каждом из рангов было одинаковым. Для каждой строки возвращается номер ранга, которому она принадлежит (листинг 1.15). Синтаксис
Результат выполнения функции NTILE() показан на рис. 1.13.
Оператор TOPВ новой версии сервера оператор TOP можно использовать в любых предложениях языка DML, а не только в предложении SELECT, аргументом может быть не только число, но и выражение. Все остальные конструкции оператора остались без изменений. Пример использования оператора TOP показан в листинге 1.16. Описание Оператор TOP возвращает "верхние" строки набора в соответствии с порядком сортировки, указанным в предложении ORDER BY. Синтаксис
Результатом выполнения оператора TOP будет набор из 8 (4 х 2) строк, показанный на рис. 1.14.
Предложение TABLESAMPLEС помощью предложения TABLESAMPLE можно выбирать множество строк, в отличие от оператора TOP не "верхние" строки, а произвольные. Структура набора сохраняется до тех пор, пока не произойдут изменения в строках. Указав номер набора в операторе REPEATABLE, можно повторно возвращать один и тот же набор. Синтаксис
Описание
В листинге 1.17 приведен пример использования предложения TABLESAMPLE.
Новые возможности в обработке ошибокВ предыдущей версии SQL Server нельзя было создать пользовательский обработчик ошибок. Для обработки ошибок пользовались либо триггерами, либо создавали обработчик на клиентском приложении, что не соответствовало требованиям объектно-ориентированного программирования и многоуровневой клиент-серверной архитектуре. Работа с ошибками была утомительна еще из-за переменной @@ERROR, устанавливаемой на каждый оператор и проверяемой после выполнения каждой операции. Блок TRY…CATCHВ новую версию сервера добавлен блок TRY…CATCH для обработки исключительных ситуаций (ошибок). Описание Обработчик состоит из блока TRY, где находится выполняемый код, и блока CATCH, в котором происходит перехват ошибки. Синтаксис
Пример создания хранимой процедуры с использованием нового обработчика ошибок показан в листинге 1.18.
Внутри блока-"ловушки" доступны новые функции для обработки исключений:
Таким образом, можно получить не только номер ошибки (как при использовании @@ERROR), а всю доступную информацию для обработки и отправки на клиентское приложение. Функция XACT_STATE()Новая функция XACT_STATE(), возвращающая информацию о состоянии транзакции, используется для обработки оператора, логическая часть которого попадает в блок-"ловушку" и может приводить к невыполнимой транзакции. Пример создания хранимой процедуры с использованием функции, возвращающей состояние транзакции, приведен в листинге 1.19.
Состояние XACT_STATE() = 0 обозначает, что нет открытых транзакций. Новый тип триггеров - DDL-триггерВ новой версии SQL Server появились новые виды триггеров - DDL-триггеры, которые могут использоваться как для программирования приложений, так и для решения административных задач и позволяют отслеживать выполнение DDL-операторов в системах, где пользователи самостоятельно создают объекты базы данных. DDL-триггеры, в отличие от стандартных DML-триггеров, "срабатывают" на события, порождаемые операциями создания (CREATE), модификации (ALTER) и удаления (DROP) объектов SQL Server. Полный перечень событий, на которые реагируют триггеры, можно найти в справочной системе по MS SQL Server 2005. Синтаксис
Пример использования DDL-триггера приведен в листингах 1.20-1.22.
Полученное в результате сообщение об ошибке показано на рис. 1.15.
РезюмеВ данной главе рассмотрены только основные изменения Transact-SQL, другие возможности языка будут описаны в следующих главах. В целом язык Transact-SQL стал значительно мощнее и приобрел новые функциональные свойства, что укрепит позиции корпорации Microsoft на рынке реляционных баз данных.
Страница сайта http://silicontaiga.ru
Оригинал находится по адресу http://silicontaiga.ru/home.asp?artId=5041 |